Searching designed by users
In 1995 when the PEP Archive was first envisaged full text searching was rare, Internet searches were slow and results were often convoluted and unhelpful.
The criteria that PEP set out for a search facility (at first using DVD technology) were devised by Peter Fonagy (then Chair of the UK Institute of Psychoanalysis Publication Committee and an internationally renowned psychoanalytic scholar and researcher) and David Tuckett (then Editor of the International Journal of Psychoanalysis). They determined that it should be possible to use full text and powerful search operators (proximity, phrase, thesaurus, Boolean and so on) and so do away with the arbitrary results obtained from keyword, title and abstract searches. However, they also wanted results to be presented in clean, frugal, intuitive and user-friendly ways.
Instead of displaying results ordered by journal, year and then author, with numerous opportunities to click and expand levels producing more and more complex screen layouts (a structure common at the time), they conceived the ATOC formula whereby the entire PEP database of tens of thousands of articles would be organised in standard bibliographic format – author, year, title, source – with or without surrounding text.
Their ambition to provide full text searching meant that every word had to be indexed and a whole series of other entities coded – paragraph, section, section headings, bibliography and so on. They also asked that other entities be indexed such as article type, year, journal and journal volume and part, and that dream text, dialogue and case material be separately tagged and so independently searchable.
Further detail is provided below as to how these requests have been superbly implemented with special customization by PEP’s technical consultant, Neil Shapiro.
As search technology has evolved since 1995 the original approach has been extended; today the online version of the PEP archive (PEP-Web) offers a variety of sortable output, including exports of bibliographies to Microsoft Word documents or Endnote and similar bibliographic database systems. The full text of the PEP archive is also fully indexed by Google and so fully searchable from Google and Google Scholar.
PEP’s search engine technology has always been selected from the leaders in the field. By 2008 a Mark III web interface will have been developed and launched with many new features arising from consultations with scholars – such as the capacity to do instant look-ups to explore controversies over the meaning of core psychoanalytic terms or to list which articles are most cited by authors or downloaded by web users.
Careful selection of authoritative texts across commercial publishers
The starting point for selection of publications has been quality and breadth of knowledge.
As the outcome of a partnership between the publishers of the two leading peer-reviewed publications in psychoanalysis, the PEP archive was from the start intended to be an inclusive collection of the available work of the most important psychoanalytic writers, independent of who published them – an unusual development in a world where the major publishers have developed Internet platforms based on their holdings rather than a subject area.
The five most important peer-reviewed English language journals were the natural starting point – marking an unusual inter-publisher co-operation – and twenty-four have been added since, with more in the pipeline. PEP estimates that the value at cost of the print versions of journals and books in the archive (version 7) stands at around $150,000.
Because many psychoanalytic authors write books rather than contributing to journals and Freud’s correspondence and collected work are in book form, an early decision was taken to include some books as well as journals. Gradually, PEP has expanded the archive to include books by leading psychoanalytic authors. Then, in 2006, PEP achieved a very considerable step towards the creation of a complete archive, obtaining the electronic rights to the Standard Edition of Freud’s work and setting out to engineer its first electronic publication in a manner that would build on the legendary editorial skill exercised by James Strachey in producing the printed edition.
In 2009, PEP was able to add the Gesammelte Werke (the German version of the Standard Edition of the Complete Psychological Works of Sigmund Freud). Imagine now being able to compare the two Freud Standard Edition Texts in English and German, page by page. With the implementation of our new Mach III Search Engine, it will be a scholars dream as they will now have an exceptional and extraordinary opportunity to read and compare Freud translations.

The PEP Board in 2006, charged a group of internationally renowned psychoanalytic scholars under the chairmanship of Dr Robert Michels (Joint Editor of the International Journal of Psychoanalysis and Deputy Editor of the American Journal of Psychiatry) to form an advisory committee to review how the PEP Archive technology was working and to advise on additional features and content. Their recommendations were accepted by the Board during 2007 and are currently being implemented. They include the creation of a permanent international scholars’ advisory group, the further development of the search interface (just described) and the addition of Freud’s work in German, which will be linked paragraph by paragraph to the Strachey translation. These ideas will guide additions to the PEP Archive over the next few years.
From source text to screen: a quality digitization process
Over the course of the years that PEP has been producing the PEP Archive, we have developed and evolved our digitization process with two things in mind: functionality and quality. The full-text content in the PEP Archive boasts textual accuracy of 99.995 percent. To achieve this level of quality, we have spent over 1.5 million dollars on digitization over the last decade.
From the time PEP collects the journals and books to be digitized to the time we finalize it into the PEP Archive, considerable effort goes into adding value to the data, while ensuring its integrity. There are a number of key technologies and processes that need to be instituted and coordinated to make this effort practical and effective:
1. A text encoding method focused on structure and semantics rather than formatting.
2. A means of automatically checking structure and semantics
3. A complementary manual (human) process for checking structure and semantics
4. Expertise in the subject area to design and guide what functionality should be implemented in a given data source. Expertise in design of markup, and a good flexible document type definition, to accommodate and adapt to those needs.
5. A thorough analysis of the journals and books being handled, to allow automation of navigational structures beyond the basic page and citation jumps.
6. A means of correcting and dealing with publication errors, particularly when it impacts navigational or search results.
7. Effective automation of processes to maintain such a huge (and growing) database of the literature. Maintenance is required when new data is added to the database, since all the data must be reprocessed and re-checked against the new data for accuracy of links and external references. 8. Further, when new data functionality is added, such as a new type of link or query, changes must sometimes be propagated throughout the data.
9.Overarching management, and effective and quick communications and organization among the agents working on the various components of the data flow. When something goes wrong, the process must catch it in time to stop it affecting a large amount of data.
The unifying goal of all the above technology and process requirements is to allow a single source format and set of data to serve and be used in many different applications and research analyses of the database: one that meets the needs of the PEP research and practitioner community, and that evolves easily with the requirements for such applications.
The figure below shows a data flow of the process as it is seen today. Although it is not necessary for us to scan all the paper materials before we begin conversion and processing, we scan everything, because we’ve learned that our Quality Assurance (QA) process operates more effectively if we can go back and easily refer to the source documents at any time-and having an electronic image of the original allows us to do that efficiently, even automatically.
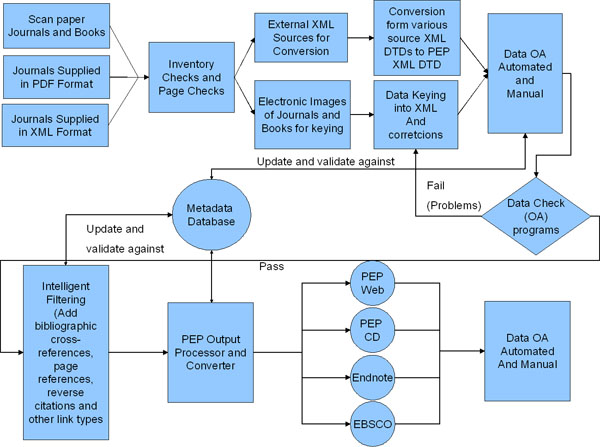
Data then begins the long and expensive process of conversion. The required effort and cost is increased greatly by the requirements for accuracy, both of the data that’s keyed, the illustrations that are scanned, and the post-keying preparation for intelligent electronic access.
There are three key aspects of the data flow to observe in the preceding chart:
1. Metadata -information about each article or book in the PEP database, and those just being processed-are captured early in the process, and used throughout for QA. The metadata help catch problems with external references which could potentially occur in the keying, markup, or the original source data
2. Extensive Data QA is key to the process, and applied through the entire life cycle.
3. The use of a logical encoding scheme-the eXtensible Markup Language ( XML) allows us to use a single source of data for multiple output applications (PEP-Web, PEP DVD, Endnote, EBSCO).
Metadata Collection
The metadata collection and usage in this process is at the heart of PEP’s Intelligent Data Markup and QA. In the paper-based publishing world, mistakes can make it through the editing process and into the publication. It’s not possible to correct the published data, so in those cases, errata are issued in a later journal or edition. However, for an electronic database with extensive cross-referencing links and value added functions, information that has been corrected through errata, or information which was not caught and remains incorrect, can cause problems and loss of functionality. So this is a big part of the PEP post keyboarding QA process.
Extensive Data QA
In addition, a suite of both syntax and semantic tests are run against the data as they are completed by the keyboarding contractors. The subsequent stages of processing and filtering of data for output to various applications include additional integrity checks to assist both the QA process and the automation to add intelligent links and functionality to the data. A vigorous QA program is maintained all through the process to ensure content inclusion and accuracy.
For example, one very common source of uncorrected errors is bibliographies. References in bibliographies too often cite the incorrect page start for an article, or even refer to the wrong volume or year of a publication. And often non-standard journal abbreviations are used-and occasionally, even the wrong journal name-making it difficult to automate the process of external linking. Combine two or more of these problems and you can see how it can be difficult to use bibliographic data to enhance the usability of publications by providing a link to the referenced book or article.
But PEP has developed programs that work in the QA process to correct or at least correctly link from references which include “misinformation” (and devotes a large amount of manual effort to the problem as well). Throughout the PEP data quality assurance process, PEP gathers the actual article metadata and compares all references to that data. This allows us to amend incorrect information in the reference sections of articles when necessary, or at a minimum to automate the link to the destination article so that it is preformed correctly. While correcting these errors alters the data from a “historical” perspective, it allows data to be used more readily and ensures that researchers and practitioners will have the correct information to conduct their studies.
XML
XML is a key part of what makes this process possible. This is a data markup language where you add “tags” surrounding the original data to identify “objects” in the data, such as references, citations, and of course, the article “metadata”, the title, author, page breaks, publisher, etc. These tags can each also contain a number of “attributes”, which are not typically part of the original data itself, but can store data about the object that’s being tagged that is useful in processing.
The XML coding is different than traditional text formatting languages because it is focused on marking text with regard to its purpose, rather than presentation. For example, a quotation, which is usually in italics, is not marked for italicized font. Rather, it is marked as a quotation. The formatting of the quotation is decided by a style sheet, at final output time, which is basically just before it is presented to you on the web.
Such logical markup allows us to develop programs to search and link data intelligently. In PEP, for example, you can search for words within quotations, in patient therapist dialogue, and in dreams. You can search within abstracts, titles and references, separately from the rest of the document. It even helps us to improve the precision of searching. We exclude the reference section from “general” full text searches by design.
Logical markup also allows us both to control presentation and to do data extraction and research. While PEP preserves the original page numbering and divisions of the source material, the actual display (fonts, sizes, and text width) are controlled in the final output. In this manner, PEP can adjust the presentation to fit different screen sizes, or to accommodate special needs. In fact, with PEP’s XML markup, the archive data can be reformatted and re-assigned for different needs: from bibliographical summaries, current-contents style abstracting, to complete full-text presentation. (Of course, while we often refer to the complete output as “full-text”, all the original graphics are included and displayed in the same context as the original.)
The XML markup is also a key component of the QA methodology. For accuracy and quality reasons, we use a strict “validating” form of XML which requires that all documents adhere to a document structure template, called a “Document Type Definition”, or DTD. This allows us to specify parts of each document that are “required”, and the XML parser quickly identifies documents which are missing any such logical data. For example, part of the metadata for any given document in PEP is a publication year. If the parser detects that publication year markup is missing from the document, then the document is flagged as in error. However, it is still possible that the year markup was included, but the information in the year tags is “empty” or otherwise not valid. That’s where semantic checking comes in. We run semantic rule checks on the data, checking that the tagged data:
1) complies with the form of data required
2) is in the range of valid data (sometimes that requires a lookup in the metadata)
Example. To show you the transformation, the next series of figures will show you the original scan of a page of text from Freud SE, then the markup in plain text (where for presentation, we changed the tags and special character place holders to a bold font), in an XML editor, showing a slight improvement in readability for editing, and finally as it is presented in PEP-Web.
Here is a sample of an original scanned page from Freud SE (page 24 of Volume 1). This is sent to a keyboarding company, which keys the text twice for 99.995% accuracy.

This is shown in the final keyed XML in the next figure. (Note that this figure also includes the metadata and contents of Page 23, and does not show “all” of page 24 for the sake of brevity.)
<pepkbd3>
<artinfo arttype=”ART” j=”SE”>
<artyear> 1886 </artyear>
<artbkinfo extract=”SE.001.0000A” prev=”SE.001.0017A” next=”SE.001.0033A”/> <artvol>1 </artvol>
<artpgrg> 23-31 </artpgrg>
<arttitle postdata=”(1886)”> Observation of a Severe Case of Hemi-Anaesthesia in a Hysterical Male</arttitle>
<artauth>
<aut><nfirst> Sigmund </nfirst> <nlast> Freud </nlast></aut>
</artauth>
</artinfo>
<body>
<pb><n> 23 </n></pb>
<unit rtitle=”true” year=”1966″><h1> Editor’s Notes </h1>
<h2> Beobachtung Einer Hochgradigen Hemi-Anästhesie Bei Einem Hysterischen Manne </h2>
<authsectinfo>
<hauth><aut><nfirst> James </nfirst> <nlast> Strachey </nlast></aut></hauth>
</authsectinfo>
<p> (a) German Edition: <binc id=”B001″><y> 1886 </y> <j> Wien. med. Wschr. </j> , <v>36 </v> ( <bs> 49 </bs> ), <pp> 1633-38 </pp> . </binc> (December 4.) </p>
<p> This paper seems never to have been reprinted. The present translation, by James Strachey, is the first into English. It was apparently intended that this should be the first of a series of papers, since there is a superscription which reads ‘ <i>Beitr ä ge zur Kasuistik der Hysterie </i> , I’ (Contributions to the Clinical Study of Hysteria, I). But the series was not continued. </p>
<p> On October 15, 1886, some six months after his return from Paris, Freud read a paper before the Vienna ‘ Gesellschaft der Aerzte ’ (Society of Medicine) with the title ‘Über m ä nnliche Hysterie ’ (On Male Hysteria). The text of this paper has not survived, though reports of it appeared in the Vienna medical periodicals: for instance, in the <binc id=”B002″><j> Wien. med. Wochenschr. </j> , <v> 36 </v> ( <bs> 43 </bs> ), <pp> 1444-6</pp></binc> (October 23). It is also shortly summarized by Ernest Jones ( <bxe rx=”SE.001.0399A.B129″> 1953 </bxe> , <pgx rx=”SE.001.0399A.B129″> 252 </pgx> ). Freud himself gives an account of the occasion in his <i> Autobiographical Study </i>
However, since XML is a standard which is used in many applications, we have tools which allow us to edit the document in a more readable and manageable fashion. For example, the figure below shows the same text presented in XMetal, an XML Editor which uses the markup to structure and formats the text for editing. Here the tags are shown by symbols, with the tag name embedded.

Finally, in this last figure, we show this same information as it appears on PEP Web.

In summary, we’ve seen that XML and the PEP DTD allow us to:
• Mark up the logical structure of the documents
• Mark up and identify the metadata, such as author information
• Separate formatting from the data, so we can determine the details of the display according to the medium.
• Use the Metadata and markup to perform both structural and semantic QA, to ensure data integrity.
Encoding and indexing: ensuring fast and frugal searching, accuracy and relevance
In the previous section, we referred to PEP’s markup as “Intelligent Data Markup”. We alluded to the fact that the markup provides enhanced cross-reference (linking) features based on not only the data presented, but a validation of that data to ensure that the cross-reference can be “followed” to the intended location.
But the PEP archive depends on much more than just predefined and validated links to provide navigational and research aids. The archive is designed for:
• Fast full-text search, where every word is searchable (there are only a few common words that are not indexed). Phrases can be searched as well as word patterns. The PEP DVD currently allows even more precision in specifying a search.
• Search within document structure. Most logical document structures are identifiable by their tagging, and searches may be conducted using any logical element as well as by their context in the document. Of course, what you can search also depends on the current user interface to the search engine. On PEP-Web, you can currently search any of the document metadata fields (author, title, source), the type of article, (e.g., search only reviews or commentaries), and you can restrict the range of the search to a logical area such as a quote, dream, dialogue, volume, or year. There are a lot more capabilities for taking advantage of fielded, full-text search already included in the data markup, which we will bring out to the interface in 2008.
• Return of data in bibliographic form. By bringing back results as bibliographical data, linked to the article, you get a reusable, top down look at the articles which match your criteria. Then, you can drill down into each and see the matches, in context. In order to make this more useful, a number of books-especially compilations-are coded as separate articles, in a common source (the book). This also includes individual letters in a book covering correspondence.
The bibliographical results design, which we refer to as “ATOC” (Author- Alphabetical Table of Contents) requires some extra steps during data conversion and coding. As usual, we must do a thorough document analysis of each book. Some compilation books split easily, much like journal issues divide into articles; but others require additional decisions and effort. Although the book is split, we must still accommodate page links within the book, and cross-references to any common resources like a bibliography at the end of the book or end notes. And while we can regenerate (so we don’t rekey) journal Tables of Contents (TOCs), we do key an exact copy of the book TOCs, so you can view the book as it was originally organized, as well as the ATOC resulting from our logical split. Lastly, while the parts of a ‘logically split’ book will come back in alphabetic rather than page order, we add navigation links to allow you to quickly go to the next part of a book, the previous part, and the table of contents.
XML encoding of original texts allows works to be divided into content elements – such as chapter headings, paragraphs, footnotes, endnotes and illustrations – and recognised accordingly. For example, elements distinguished by the encoding scheme include passages of dialogue between patient and analyst, dream material scenes, and many varieties of reference. Marking up texts provides a route through vast amounts of data, enabling users to conduct different searches ranging from simple keyword searches to advanced searches combining a number of different data fields. Bibliographic acknowledgements are included, which means that the electronic version of the text can be cited in research papers and publications. Copyright material is clearly marked as such.
The PEP design using ATOC organization and the PEP XML DTD facilitate highly sophisticated indexing of information and give us the infrastructure to keep enhancing search and retrieval capabilities well into the future.